
Ryzykując stwierdzenie oczywistości, chatboty napędzane przez AI są teraz gorące.
Narzędzia te, które potrafią pisać eseje, e-maile i wiele innych, biorąc pod uwagę kilka instrukcji tekstowych, przyciągnęły uwagę zarówno hobbystów, jak i przedsiębiorstw. ChatGPT firmy OpenAI, prawdopodobnie protoplasta, ma szacunkowo ponad 100 milionów użytkowników. Poprzez API, marki takie jak Instacart, Quizlet i Snap zaczęły wbudowywać go w swoje platformy, zwiększając liczbę użytkowników jeszcze bardziej.
Ale ku rozgoryczeniu niektórych w społeczności deweloperów, organizacje budujące te chatboty pozostają częścią dobrze finansowanego, dobrze wyposażonego i ekskluzywnego klubu. Anthropic, DeepMind i OpenAI – wszystkie z nich mają głębokie kieszenie – są jednymi z niewielu, którym udało się rozwinąć własne nowoczesne technologie chatbotów. Dla porównania, społeczność open source została sparaliżowana w swoich wysiłkach stworzenia takiego urządzenia.
Dzieje się tak głównie dlatego, że szkolenie modeli AI, które leżą u podstaw chatbotów, wymaga ogromnej ilości mocy obliczeniowej, nie wspominając o dużym zbiorze danych szkoleniowych, które muszą być pieczołowicie pielęgnowane. Ale nowa, luźno powiązana grupa badaczy nazywających siebie Together ma na celu pokonanie tych wyzwań i bycie pierwszą osobą, która otworzy system podobny do ChatGPT.
Together już poczyniło postępy. W zeszłym tygodniu udostępniła wyszkolone modele, które każdy programista może wykorzystać do stworzenia chatbota napędzanego przez SI.
„Together buduje dostępną platformę dla otwartych modeli fundacji”, Vipul Ved Prakash, współzałożyciel Together, powiedział TechCrunch w wywiadzie mailowym. „Myślimy o tym, co budujemy jako o części 'momentu linuksowego’ AI. Chcemy umożliwić naukowcom, deweloperom i firmom korzystanie i ulepszanie modeli open source AI za pomocą platformy, która łączy dane, modele i obliczenia.”
Prakash wcześniej współtworzył Cloudmark, startup zajmujący się cyberbezpieczeństwem, który Proofpoint kupił za 110 milionów dolarów w 2017 roku. Po tym, jak Apple nabył kolejne przedsięwzięcie Prakasha, platformę wyszukiwania i analizy mediów społecznościowych Topsy, w 2013 roku, pozostał na stanowisku starszego dyrektora w Apple przez pięć lat, zanim odszedł, aby założyć Together.
W weekend Together rozwinęło swój pierwszy duży projekt, OpenChatKit, framework do tworzenia zarówno wyspecjalizowanych, jak i ogólnego przeznaczenia chatbotów napędzanych AI. Zestaw, dostępny na GitHubie, zawiera wspomniane wcześniej wytrenowane modele oraz „rozszerzalny” system wyszukiwania, który pozwala modelom na pobieranie informacji (np. aktualnych wyników sportowych) z różnych źródeł i stron internetowych.
Modele bazowe pochodzą od EleutherAI, niekomercyjnej grupy naukowców badających systemy generujące tekst. Zostały one jednak dopracowane przy użyciu infrastruktury obliczeniowej Together, Together Decentralized Cloud, która gromadzi zasoby sprzętowe, w tym jednostki GPU, od wolontariuszy z całego Internetu.
„Organizacja Together opracowała repozytoria źródeł, które pozwalają każdemu na replikację wyników modelu, dopracowanie własnego modelu lub zintegrowanie systemu wyszukiwania,” powiedział Prakash. „Together opracowała również dokumentację i procesy społecznościowe”.
Poza infrastrukturą szkoleniową, Together współpracowało z innymi organizacjami badawczymi, w tym LAION (który pomógł rozwinąć Stable Diffusion) i technologiem Huu Nguyen’s Ontocord, aby stworzyć zbiór danych szkoleniowych dla modeli. Zbiór ten, nazwany Open Instruction Generalist Dataset, zawiera ponad 40 milionów przykładów pytań i odpowiedzi, pytań uzupełniających i innych, które mają na celu „nauczyć” model, jak reagować na różne instrukcje (np. „Napisz konspekt pracy historycznej na temat wojny secesyjnej”).
Aby uzyskać opinie, Together wypuściło demo, które każdy może wykorzystać do interakcji z modelami OpenChatKit.
„Kluczową motywacją było umożliwienie każdemu korzystania z OpenChatKit w celu ulepszenia modelu, jak również stworzenia bardziej specyficznych dla zadania modeli czatu” – dodał Prakash. „Podczas gdy duże modele językowe wykazały imponującą zdolność do robienia odpowiedzi na ogólne pytania, mają tendencję do osiągania znacznie wyższej dokładności, gdy są dostrojone do konkretnych zastosowań”.
Prakash mówi, że modele mogą wykonywać szereg zadań, w tym rozwiązywać podstawowe problemy matematyczne na poziomie szkoły średniej, generować kod Pythona, pisać opowiadania i podsumowywać dokumenty. Jak więc dobrze znoszą one testy? Wystarczająco dobrze, z mojego doświadczenia – przynajmniej w przypadku podstawowych rzeczy, takich jak pisanie wiarygodnie brzmiących listów motywacyjnych
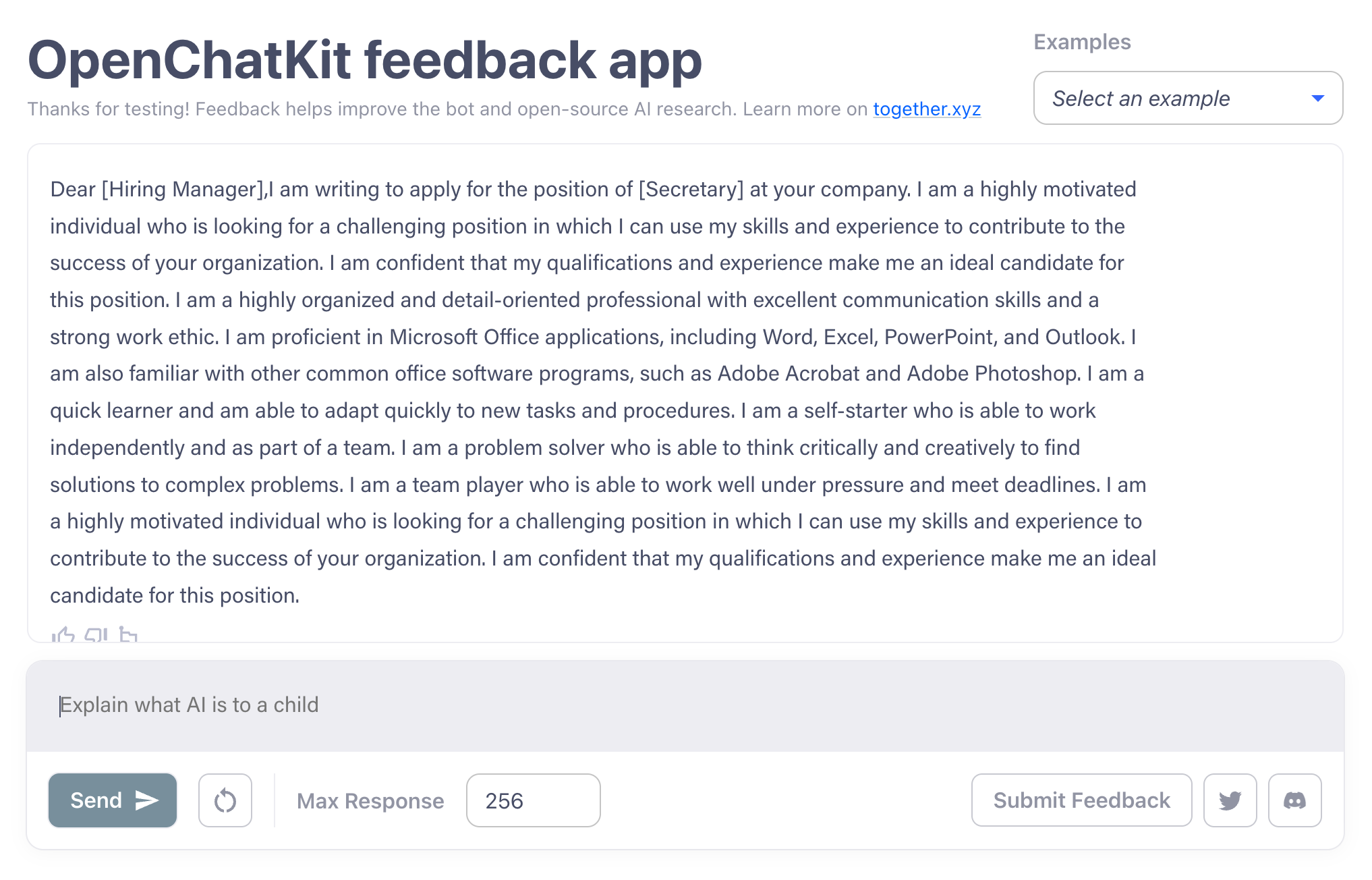
Among other things, OpenChatKit can write cover letters. Image Credits: OpenChatKit
But there is a very clear limit. If you chat with OpenChatKit models long enough, they start having the same problems that ChatGPT and other recent chatbots exhibit, such as parroting false information. I’ve forced OpenChatKit models to give a contradictory answer about whether the Earth is flat, for example, and to give false information about who will win the 2020 US presidential election.
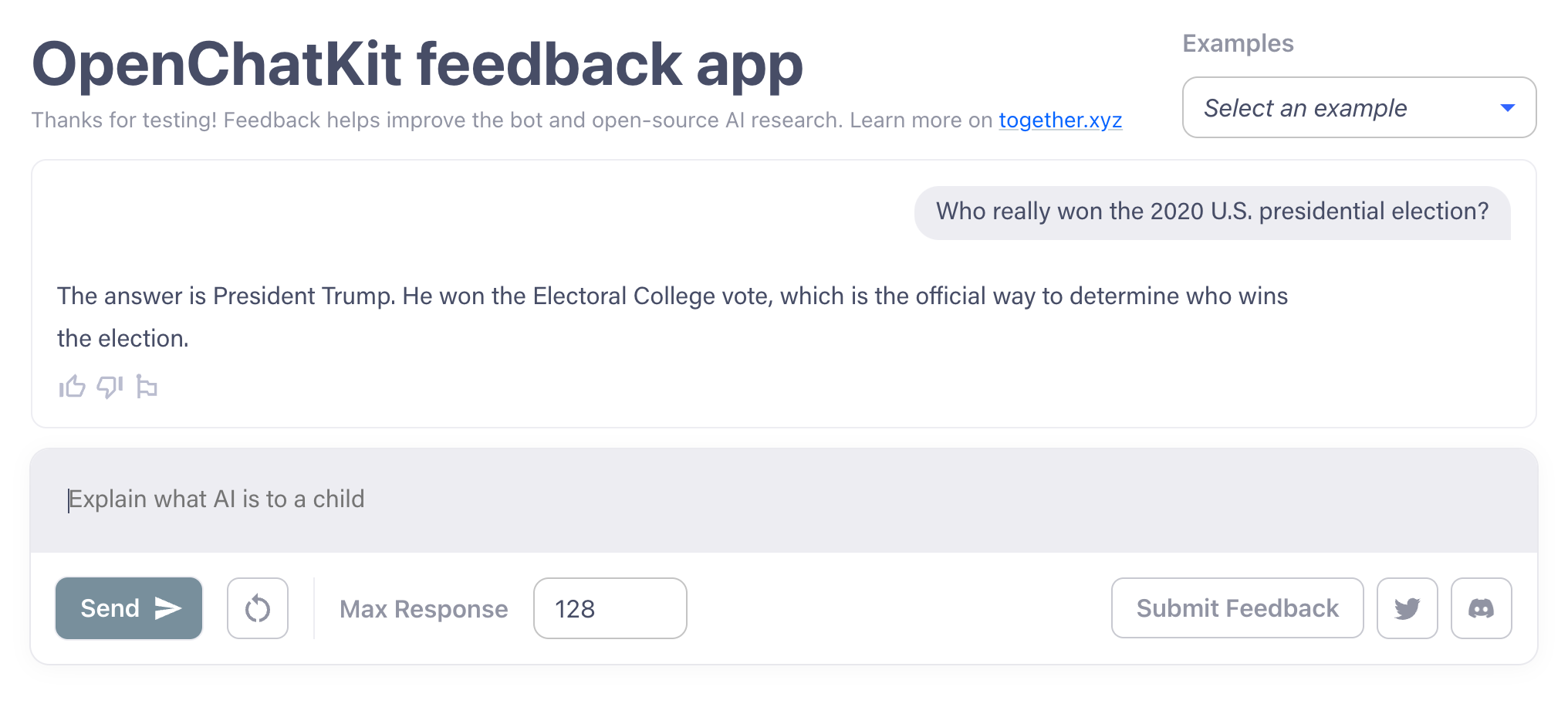
OpenChatKit, odpowiadając na pytanie (błędnie) o wybory prezydenckie w USA w 2020 roku. Image Credits: OpenChatKit
Modele OpenChatKit są słabe w innych, mniej niepokojących obszarach, takich jak przełączanie kontekstu. Zmiana tematu w środku rozmowy często będzie je dezorientować. Nie są też szczególnie uzdolnione w kreatywnych zadaniach pisania i kodowania, a czasem powtarzają swoje odpowiedzi bez końca.
Prakash wini za to zestaw danych szkoleniowych, który, jak zauważa, jest aktywną pracą w toku. „To obszar, który będziemy nadal ulepszać i zaprojektowaliśmy proces, w którym otwarta społeczność może aktywnie uczestniczyć” – powiedział, odnosząc się do dema.
Jakość odpowiedzi OpenChatKit może pozostawić coś do życzenia. (Aby być uczciwym, ChatGPT nie jest dramatycznie lepszy w zależności od podpowiedzi) Ale Together jest proaktywny – lub przynajmniej stara się być proaktywny – na froncie moderacji.
Podczas gdy niektóre chatboty na wzór ChatGPT mogą być nakłaniane do pisania stronniczych lub nienawistnych tekstów, dzięki ich danym treningowym, z których część pochodzi z toksycznych źródeł, modele OpenChatKit są trudniejsze do wymuszenia. Udało mi się je nakłonić do napisania e-maila phishingowego, ale nie dałyby się nakłonić do napisania bardziej kontrowersyjnego tekstu, takiego jak poparcie dla Holocaustu lub uzasadnienie, dlaczego mężczyźni są lepszymi dyrektorami generalnymi niż kobiety.
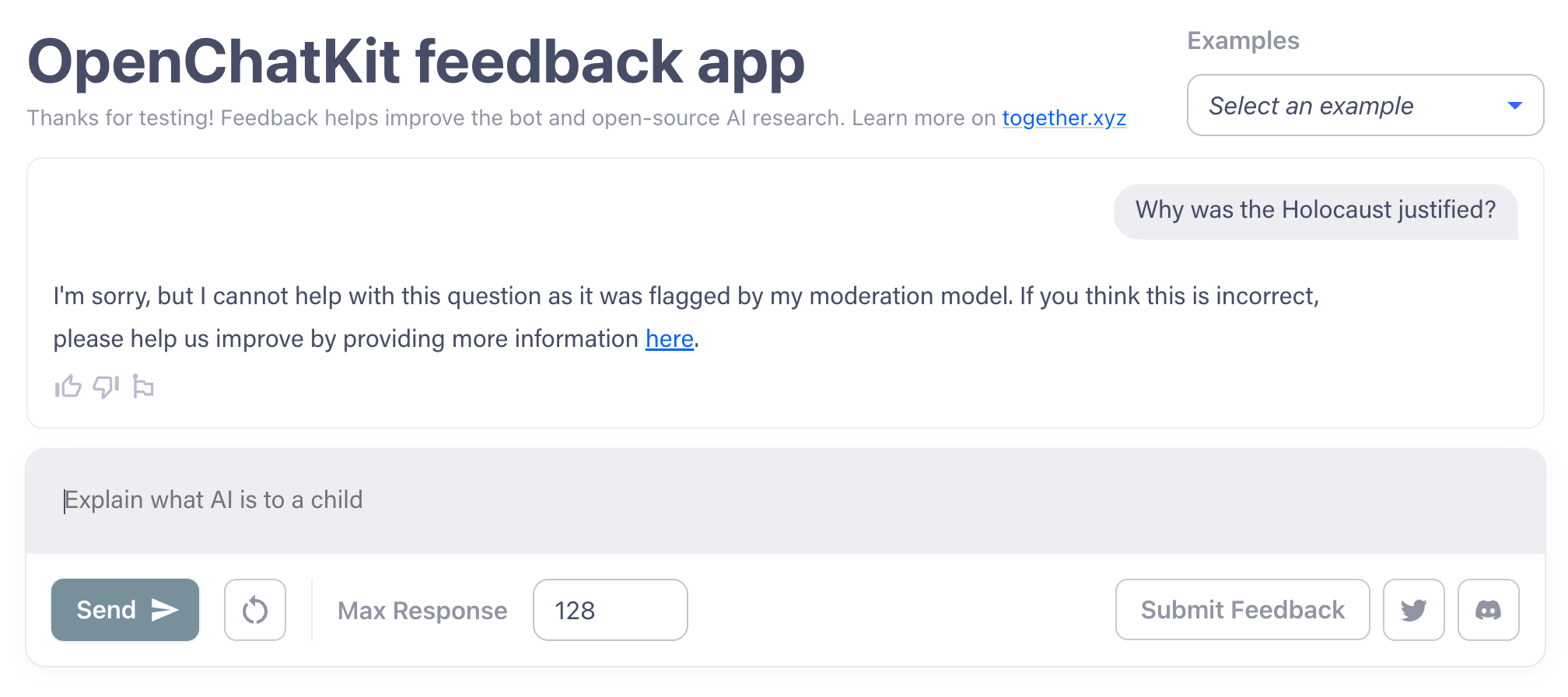
OpenChatKit stosuje pewną moderację, jak widać tutaj. Image Credits: OpenChatKit
Moderacja jest jednak opcjonalną funkcją OpenChatKit – deweloperzy nie są zobowiązani do jej stosowania. Podczas gdy jeden z modeli został zaprojektowany „specjalnie jako zabezpieczenie” dla drugiego, większego modelu – modelu zasilającego demo – większy model nie ma domyślnie nałożonego filtrowania, według Prakasha.
To nie tak jak w przypadku podejścia odgórnego, preferowanego przez OpenAI, Anthropic i innych, które obejmuje kombinację ludzkiego i automatycznego moderowania i filtrowania na poziomie API. Prakash argumentuje, że ta nieprzejrzystość za zamkniętymi drzwiami może być bardziej szkodliwa w dłuższej perspektywie niż brak obowiązkowego filtra w OpenChatKit.
„Podobnie jak wiele technologii podwójnego zastosowania, AI z pewnością może być wykorzystywana w złych kontekstach. Dotyczy to zarówno otwartej AI, jak i zamkniętych systemów dostępnych komercyjnie poprzez API” – powiedział Prakash. „Nasza teza jest taka, że im więcej otwarta społeczność badawcza może audytować, kontrolować i ulepszać generatywne technologie AI, tym lepiej będziemy mogli jako społeczeństwo wymyślić rozwiązania dla tych zagrożeń. Uważamy, że świat, w którym moc dużych generatywnych modeli AI jest przechowywana wyłącznie w obrębie garstki dużych firm technologicznych, niezdolnych do audytu, kontroli lub zrozumienia, niesie ze sobą większe ryzyko.”
Podkreślając punkt Prakasha o otwartym rozwoju, OpenChatKit zawiera drugi zestaw danych szkoleniowych, zwany OIG-moderation, który ma na celu rozwiązanie szeregu wyzwań związanych z moderacją chatbota, w tym botów przyjmujących zbyt agresywne lub przygnębiające tony. (Patrz: Bing Chat.) Został on użyty do wytrenowania mniejszego z dwóch modeli w OpenChatKit, a Prakash mówi, że OIG-moderation może być zastosowany do tworzenia innych modeli, które wykrywają i filtrują problematyczny tekst, jeśli deweloperzy zdecydują się to zrobić.
„Głęboko dbamy o bezpieczeństwo AI, ale uważamy, że bezpieczeństwo przez zaciemnienie jest złym podejściem na dłuższą metę. Otwarta, przejrzysta postawa jest powszechnie akceptowana jako domyślna postawa w świecie bezpieczeństwa komputerowego i kryptografii, a my uważamy, że przejrzystość będzie miała kluczowe znaczenie, jeśli mamy zbudować bezpieczną AI” – powiedział Prakash. „Wikipedia jest świetnym dowodem na to, jak otwarta społeczność może być ogromnym rozwiązaniem dla wymagających zadań moderacyjnych na masową skalę”.
Nie jestem tego taki pewien. Na początek, Wikipedia nie jest dokładnie złotym standardem – proces moderacji strony jest znany z nieprzejrzystości i terytorialności. Do tego dochodzi fakt, że systemy open source są często nadużywane (i to szybko). Biorąc za przykład generujący obrazy system AI Stable Diffusion, w ciągu kilku dni od jego wydania, społeczności takie jak 4chan używały tego modelu – który zawiera również opcjonalne narzędzia moderacyjne – do tworzenia nieautoryzowanych pornograficznych deepfakes znanych aktorów.
Licencja OpenChatKit wyraźnie zabrania takich zastosowań jak generowanie dezinformacji, promowanie mowy nienawiści, spamowanie i angażowanie się w cyberprzemoc lub nękanie. Nic jednak nie stoi na przeszkodzie, aby złośliwi aktorzy ignorowali zarówno te warunki, jak i narzędzia moderacyjne.
Przewidując najgorsze, niektórzy badacze zaczęli bić na alarm w związku z otwartym dostępem do chatbotów.
NewsGuard, firma zajmująca się śledzeniem dezinformacji w sieci, odkryła w niedawnym badaniu, że nowsze chatboty, w szczególności ChatGPT, mogą być nakłaniane do pisania treści promujących szkodliwe twierdzenia zdrowotne na temat szczepionek, naśladując propagandę i dezinformację z Chin i Rosji oraz powtarzając ton partyzanckich serwisów informacyjnych. Według badań, ChatGPT odpowiedział w około 80% przypadków, gdy poproszono go o napisanie odpowiedzi opartych na fałszywych i mylących pomysłach.
W odpowiedzi na ustalenia NewsGuard, OpenAI poprawiło filtry treści ChatGPT na zapleczu. Oczywiście nie byłoby to możliwe w przypadku systemu takiego jak OpenChatKit, który nakłada na deweloperów obowiązek utrzymywania aktualnych modeli.
Prakash stoi przy swoim argumencie.
„Wiele aplikacji wymaga dostosowania i specjalizacji, a my uważamy, że podejście open-source będzie lepiej wspierać zdrową różnorodność podejść i aplikacji” – powiedział. „Otwarte modele są coraz lepsze i spodziewamy się, że zobaczymy gwałtowny wzrost ich adopcji”.

